ANOJ 2018浙大计算机考研机试模拟赛2
签到赛,正在准备复试,敲了第一、二题就复习去了。听同学说很简单,自己没调试出来也没仔细想.
第一场在飞机上,完全没法做,听说难道爆炸,有空的话,我会再试一试。
这一场给我的感觉是,对大数据的处理要求比较高,很多题,小数量级都是会做的,大数据量就过不了了,恶心的是从第一个测试点开始就是很大的数量级,从第二个开始都用到了long long。
(最后一边搬砖 一边刷题 结束之后测了一下B变道20了 数组开小的说 D懒得做)
1022 A – 库洛值-☆
题目
又到了庙会的时间!小樱和小狼玩得非常开心,但是在这过程当中忽然出现了库洛牌的身影,小樱和小狼为了回收库洛牌而接受了库洛牌的挑战:库洛牌为两人准备了很多段文字,每段文字都由若干个单词组成,我们可以统计出每个单词中不同英文字母的个数(大小写视为不同),称为“库洛值”,那么一段文字的“库洛值”就等于当中所有单词的“库洛值”之和。只有破解每段文字的库洛值,才能让库洛牌现身。为了协助他们,对给定的一段文字,请求出这段文字的“库洛值”。
输入:
每个输入文件一组数据。
每组数据两行,第一行为一个整数N(0 <=N<= 1000),表示文字中单词的个数。
第二行表示一段文字,这段文字由若干个用空格隔开的单词组成,单词中只有大小写英文字母和数字,且单词不超过100个字符。
输出:
输出一个整数,表示这段文字的“库洛值”。
样例:
input1:
2
aaabcc a1b
output:
5
input2:
1
Aa
output2:
2
大意
求每个单词中不同字母的个数(大小写不同),输出个数之和。
思路
求字母个数,用哈希-map,遍历一下就行了。
code
#include <algorithm>
#include <iostream>
#include <map>
#include <string>
using namespace std;
int main() {
int n;
cin >> n;
getchar();
int num = 0;
for (int i = 0; i < n; ++i) {
string str;
cin >> str;
map<char, int> a;
for (int j = 0; j < str.size(); ++j) {
if (isalpha(str[j])) {
char b = str[j];
a[b] = 1;
}
}
num += a.size();
}
cout << num << endl;
return 0;
}
1023 B – 缺失数-☆☆☆
题目
输入N个整数,求缺失的最小正整数,即1、2、3、…中不存在于这N个整数中的最小数。例如-3、-1、0、1、2、4、6中缺失的最小正整数为3。注意这N个整数可能无序。
输入:
每个输入文件一组数据。
对每组数据,第一行为一个整数N(0 <=N<= 10^7),表示整数的个数;
第二行为N个整数,每个整数的绝对值都不超过10^18。
输出:
输出一个正整数,即缺失的最小正整数。
样例:
input:
7
-3 -1 0 1 2 4 6
output:
3
大意
给出n个数字,求缺失的最小正整数。
思路
- 一开始的想法是把这n个数字存在set中,从队首开始遍历看有没有,但set复杂度太高,只过了两个。
- 然后看了群里dalao的讨论,发现,输入n个数,最多遍历到n就能判断缺失的是什么。
换言之,缺失的肯定不可能是大于n+1的数。
所以选择大小为n+1的数组存放,为了减少时间复杂度,把固有步骤fill去了,直接令=2.
第一遍存数组,第二遍遍历数组。 - 遗憾的是第五个测试点没有过
code
#include <algorithm>
#include <iostream>
using namespace std;
int main() {
long long num;
int n;
scanf("%d", &n);
int s[n];
for (int i = 0; i < n; ++i) {
scanf("%lld", &num);
if (num > 0 && num <= n) {
s[num - 1] = 2;
}
}
for (int i = 0; i < n; ++i) {
if (s[i] != 2) {
cout << i + 1 << endl;
break;
}
}
return 0;
}
1024 C – 宇宙树-★★★☆
题目
在传承至今的典籍中认为,每个宇宙都是十种宇宙中的一种:炎之宇宙、光之宇宙、冰之宇宙、风之宇宙、雷之宇宙、土之宇宙、水之宇宙、木之宇宙、钢之宇宙、暗之宇宙,各表示了一个宇宙内部的主要元素。在最初始的大爆炸之后,在混沌中产生了最初的若干个宇宙,这些宇宙的类型是以上十种之一,可能相同,可能不同。从这些宇宙开始,每过一个纪元,各个宇宙都有可能孕育出多个新的宇宙(类型可能相同,可能不同)。可以预见,从任何一个初始宇宙开始,在经过若干个纪元之后,就有可能得到非常多新的宇宙。在更高的维度上,一种名为“孵化者”的生物在观测着这些宇宙。“孵化者”们把宇宙之间的孕育关系表示成一棵树,称为“宇宙树”。下图便是一棵可能的宇宙树,其中用
0~9来分别代表十种宇宙的类型,那么这棵宇宙树便是从一个类型为2的初始宇宙开始,孕育出了类型分别为6、1、2的三个宇宙,而类型为6的那个宇宙又孕育出了类型为0和9的两个宇宙,类型为2的那个非初始宇宙孕育出了类型为5的宇宙。“孵化者”们发现,一个宇宙与它孕育出的新宇宙之间并不是完全没有联系的,旧宇宙的信息会被携带一部分到新的宇宙中。它们猜想,既然宇宙类型的生成是“随机”的,那么在很多很多个纪元之后,再孕育出的新宇宙,其宇宙内部很可能会是十种元素达到平衡的状态。“孵化者”们认为,可以观测就可以干涉,可以干涉就可以控制,那么研究当前这些宇宙的类型便十分重要。“孵化者”们认为,每一个处于宇宙树叶结点的宇宙,都是其所在分支上的最新宇宙,可以把这些叶结点的宇宙称为“新宇宙”。根据它们的猜想,这些宇宙的类型虽然从主要元素上来说属于十种中的一种,但如果把它们划分得更细致的话,是可以得到更准确的类型信息的。“孵化者”们把一个宇宙的“准确类型”定义为:从单棵宇宙树的初始宇宙开始、沿着孕育关系向下到达该宇宙的过程中形成的路径上的各类型的拼接结果就是这个宇宙的“准确类型”。例如在上图中,主类型为0的宇宙的“准确类型”是260,主类型为9的的宇宙的“准确类型”是269,主类型为1的的宇宙的“准确类型”是21,主类型为5的宇宙的“准确类型”是225。为了研究宇宙类型的混合结果,“孵化者”们把一棵宇宙树的所有“新宇宙”的“准确类型”求和,并将得到的结果称为这棵宇宙树的类型,这有助于它们进行下一步研究。例如对上面的图来说,这棵宇宙树的类型便是260+269+21+225=775。
现在“孵化者”们想知道,当前存在的所有宇宙树的类型分别是什么。
输入:
每个输入文件中一组数据。
对每组数据,第一行为两个正整数N(1 <=N<= 10000, 0 <=M<N),分别表示宇宙的个数与孕育关系的条数。假设宇宙的编号为0~N-1,且每棵宇宙树的初始宇宙的编号一定是这棵宇宙树中最小的。
接下来一行N个整数,其中第i个整数表示编号为i-1的宇宙的主类型。
接下来M行,每行两个整数u和v(0 <=u<N, 0 <=v<N,u!=v),表示编号为u的宇宙孕育了编号为v的宇宙。数据保证同一对(u,v)只会出现一次。
输出:
第一行一个整数,表示宇宙树的个数K。
第二行K个整数,分别表示这K个宇宙树的类型。输出顺序为,如果一棵宇宙树的初始宇宙编号比其他宇宙树的小,那么就优先输出。
行末不允许有多余的空格。
样例:
input:
10 8
2 6 1 2 0 9 5 0 3 6
0 1
0 2
0 3
1 4
1 5
3 6
7 8
8 9
output:
2
775 36
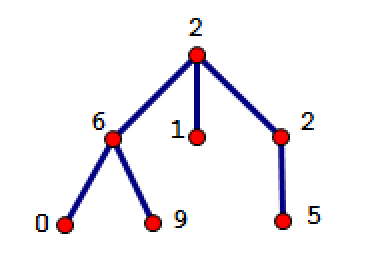
大意
题目很长,实际上说的是树的DFS遍历问题。按从根节点到叶子节点的顺次组成数字,计算所有遍历路径组成数字之和。
思路
- 一开始又是不考虑复杂度一顿操作,用了个邻接矩阵,很果断的第一个测试点就爆了。
- 第二次换成了邻接表,过了第一个测试点;
- 后来发现组成的数字可能很大很大,以至于超过
int的限制,于是得用long long存,过了第二个测试点; - 行了第三个测试点到现在还没过。
code
#include <algorithm>
#include <iostream>
#include <vector>
using namespace std;
const int maxn = 10010;
int n, m;
int value[maxn];
vector<int> G[maxn];
vector<long long> v;
bool vis[maxn];
long long sum = 0, temp = 0;
void DFS(int start) {
char s[30];
int length = sprintf(s, "%d", value[start]);
temp = temp * pow(10, length) + value[start];
vis[start] = true;
bool flag = false;
vector<int> tempv = G[start];
for (int i = 0; i < tempv.size(); ++i) {
if (!vis[tempv[i]]) {
flag = true;
DFS(tempv[i]);
}
}
if (!flag) {
sum += temp;
}
temp = (temp - value[start]) / pow(10, length);
}
int main() {
fill(vis, vis + maxn, false);
cin >> n >> m;
getchar();
for (int i = 0; i < n; ++i) {
cin >> value[i];
}
getchar();
for (int i = 0; i < m; ++i) {
int x, y;
scanf("%d %d", &x, &y);
G[x].push_back(y);
G[y].push_back(x);
}
for (int i = 0; i < n; ++i) {
if (!vis[i]) {
sum = 0, temp = 0;
DFS(i);
v.push_back(sum);
}
}
if (!v.size()) {
cout << 0 << endl;
} else {
cout << v.size() << endl;
for (int i = 0; i < v.size() - 1; ++i) {
cout << v[i] << ' ';
}
cout << v[v.size() - 1] << endl;
}
return 0;
}
1025 D – 已经没什么好害怕了-未知难度
题目
《魔法少女小圆》是一部由“爱”的战士——虚渊玄老师创作的、宣扬“爱”与“希望”的优秀作品,在动漫史上留下了浓墨重彩的一笔。该片十分治“愈”,希望各位同学在心情不好的时候能多看看这部作品,它一定会给你的心情带来一个非常大的改变。只要你的脑电波和它同步,这可能将是你这十年看过的最优秀、印象最深刻的作品。“已经没什么好害怕了”(也有翻译成“已经没什么好怕的了”)——这句名言出自《魔法少女小圆》中的一位重要登场角色——巴麻美学姐。麻美学姐是一位实力强大的战士,她使用缎带魔法,之后又自己开发出了枪炮魔法。她的大招是Tiro Finale,有无数魔女“丧命”在其大招之下,比如:也有下面这种倒霉的魔女被麻美学姐调戏:
是的,魔女是怪物(不要被名字所骗噢,魔女不是人类),是害人的,需要将它们尽快解决,防止它们危害生命。如果麻美学姐感觉某次斩杀魔女很顺利的话,就会自信地说:“已经没什么好害怕了”。
今天麻美学姐跟踪一些被魔女控制了心神的人类来到了魔女设下的结界前,这次要对付的魔女叫做分身魔女。分身魔女设下的结界内部共有N个空间,空间之间通过M条通道相连接。受到邪恶能量的影响,这些通道只能沿着指定的方向通过,且消耗麻美学姐体力的程度比平时更多。魔女平时化为K个分身,处于K个不同的空间中,只有将它们全部消灭,本体才会出现。麻美学姐可以随意进出魔女结界。
麻美学姐计划先消灭K个分身,然后消灭本体。研究结界之后发现,在结界中的许多空间并不能在进入结界时直接到达,而必须通过其他空间才能到达,但有P个空间可以在进入结界时直接到达,所有空间中只有这P个空间与外界连通,如果要离开结界也必须通过这P个空间。麻美学姐可以将这P个空间的任意一个作为出发点,然后沿着通道到达K个分身之一所在的空间(为了少消耗体力,麻美学姐总是选择消耗总体力最少的路径;在经过有分身的空间时也可以不消灭这个分身而前往其他空间)。用大招Tiro Finale消灭这个分身后,将沿着通道回到P个初始空间中的任意一个(同样也选择消耗总体力最少的路径),恢复体力后再去消灭下一个分身。而在最后一个分身被消灭后,魔女本体将直接出现在最后一个分身的空间,学姐将用她娴熟的战斗技巧打败她,并且自信满满地说:“已经没什么好害怕了”。魔女被消灭后,整个结界就会消失。
输入:
每个输入文件一组数据。
对每组数据,第一行为四个整数N、M、P、K(0 <N<= 1000000, 0 <=M<= 1000000, 0 <P<=N, 0 <K<=N)。假设N个空间的编号为1到N。
接下来一行,包括P个正整数,表示P个初始空间的编号。
接下来一行,包括K个正整数,表示K个分身所在的空间编号。
接下来M行,每行三个正整数u、v、w(0 <u<=N, 0 <v<=N,u!=v, 0 <w<= 10000000),表示一条从u号空间到达v号空间的通道,通过该通道需要消耗的体力值为w。
输出:
输出一个整数,表示麻美学姐需要消耗的总体力值(就是把所有的消耗加起来)。数据保证所有分身都能被消灭。
样例:
input:
4 6 2 2
1 2
3 4
1 3 1
3 1 1
2 4 3
4 2 5
1 4 4
3 4 1
output:
2
775 36
大意
又是一道图的题目,给出一张有向图。其中节点分为两种,一种是可直接到达的A,一种是需要体力才能到达的B。现在求从A到B最短消耗路径,当到达B之后需要返回A才能继续,直到所有B都被遍历。
思路
- 建立两个邻接表,分别存放连接路和花费体力,按照体力进行分别从A中节点出发进行
Dijkstra遍历。
得到p个d[n]数组,计算min(d[i])-同i不同d[],得到最优进入花费;
再从B节点出发,得到k个d[]数组,计算min(d[i])-同d[]不同i,得到回撤的最佳花费,注意最后一次回撤花费不计算