线上事故通报 -『9.24』 Linux内核导致服务不可用
事故说明
事故:Ali Yun ECS Linux内核导致服务不可用
Owner:滚键盘
业务:All
开始时间:2018-09-24 00:02
结束时间:2018-09-25 14:39
影响:总计39h,GMV影响为400左右
事故定级:一级事故
事故分析
事故经过
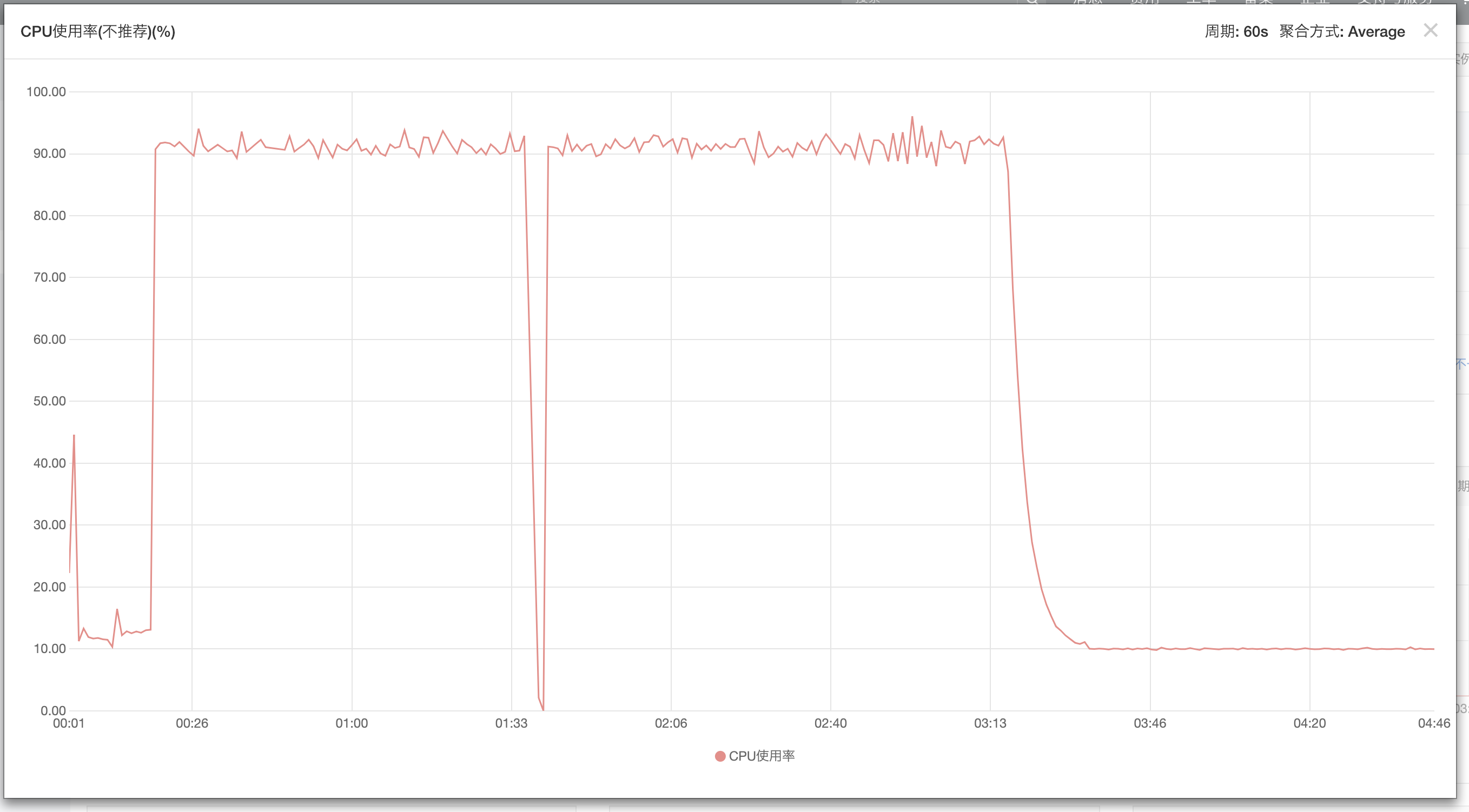
- 2018-09-24 00:02 Ali Yun 上ECS 跑完最后一次脚本任务,CPU从打满降落至11%左右,与平常回落至0%不一致,且出现ssh不能连接的现象
- 2018-09-24 00:13 在尝试解决问题未果的前提下,对实例进行正常重启操作
- 2018-09-24 00:17 ECS经过5min左右停止,重新启动后CPU彪至90%+,进入远程连接之后,显示Linux载入Error
- 2018-09-24 00:21 创建工单求助客服
- 2018-09-24 00:25 反馈CPU跑满,建议利用远程连接查看日志
- 2018-09-24 00:40 反馈日志截图
- 2018-09-24 00:43 反馈内核问题,建议先制作快照
- 2018-09-24 01:11 快照制作完毕
- 2018-09-24 01:19 授权Ali Yun操作实例
- 2018-09-24 01:41 修复失败建议初始化
- 2018-09-24 11:41 初始化之后ssh再次失效
- 2018-09-24 18:01 回滚快照之后,出现CPU跑满,Linux卡在初始化状态
- 2018-09-25 14:39 恢复服务
- 2018-09-26 15:30 恢复数据
事故反思
- 无机器监控配置,实例失常状态不可知;
- 无数据备份机制,重要日志数据极易丢失;
- 无快照备份机制,事故发生之后恢复服务困难;
- 机器配置不可理,T5突发性能实例CPU仅可用10%,CPU性能偏弱。
- 暴露了服务流程管理混乱,极易不可用,尤其是目前单实例阶段;
- 实际上事后反思是因为内存打满导致的CPU彪高,再因为重启导致的内核崩溃;
- 正确的处理方法应该是远程连接->top->M/P->k kill杀死彪高进程
- 之后10.2晚又出现相同情况,在合理操作下规避了内核崩溃的风险
恢复经验及改进:
- Linux内核尽量不升级,保持稳定可用性,谨小慎微;
- 监控报警体系需完善,安装类似『Ptrace Agent』的监控组件;
- 理清T5突发实例与正常实例的区别与联系,云厂商产品设计思路;
- 理清源码安装过程;
- 重新梳理Nginx调优步骤, 目前支持TLS1.3, h2, HSTS等;
- 了解Ali Yun从数据盘导数据流程;
- 优化pv脚本;
- 增加日志备份定时任务;
- shell->hadoop, 利用MapReduce减小内存占用,提高效率;
导数据流程
- 制作快照
- 利用快照制作云盘
- 挂载云盘(如果你能挂载上实例,当然是最好的,否则可以按量购买一台高配ECS挂载于此)
mount /dev/vdb1 /mnt挂载数据盘,切记在之前不能对数据盘分区,不能初始化数据盘,否则数据全没了- 利用
fdisk -l,df -h查看磁盘及挂载情况 - 若挂载成功,此时
/mnt就是你之前的/路径
源码安装
- wget tar.gz 文件
- tar -xzvf 压缩包
- ./configure or ./bootstrap 进行编译,此时带的参数是安装模块,安装路径等
- make 即build, 可加-j8
- make install
- cmake的安装是我见过最费内存,时间最长的,可能会提示虚拟内存不够的情况,
dd if=/dev/zero of=/swap bs=32M count=16命令扩容 - 有些编译可能会报错,可能是有些包未安装导致的