『Hadoop』MapReduce 处理 日志log(单机版)
10.2晚又出现上次CPU打满
于是痛定思痛 检查了下业务流程
发现处理日志和build两块很吃内存
尤其是日志处理,随着日志量的增大,不可避免的是处理越来越慢,对性能要求越来越高
这个时候不免想到利用MapReduce对处理过程进行分布式操作
Shell
之前在另外的blog中,我们仔细的分析了对Nginx access.log 文件如何去进行数据处理
时间上,我们可以感觉到这种bash脚本的处理方式,很轻量化
处理性能也比写java程序,cpp程序要更高效
但当数据量大起来的时候,这种做法就有些不可取
Shell对文件操作是一次性把文件load到内存中,然后再处理
如果这个时候文件比较大,到达数GB就会把内存撑爆
即使把Swap空间调到很大,也无济于事
Ps:实际上我们的log文件没有那么大,但我们的内存小呀,穷才是需求
分片分机
这个时候很容易想到,如果把数据拆分到数个文件,分配到几台机子上一起运行,那么可以解决这个问题。
但实际上怎么操作还是有一些弊端,比如说:
- 第一步对文件分片的过程仍然是顺序的,虽然内存占用不多,但速度上不去;
- 原始数据需要拷贝到其他机器上去,网络传输需要时间;
- 最重要的一个问题,这全部的过程相当繁琐,极易出错,且不够通用;
What Is MapReduce
MapReduce是一种借鉴于面向函数中map,reduce操作的分布式处理框架
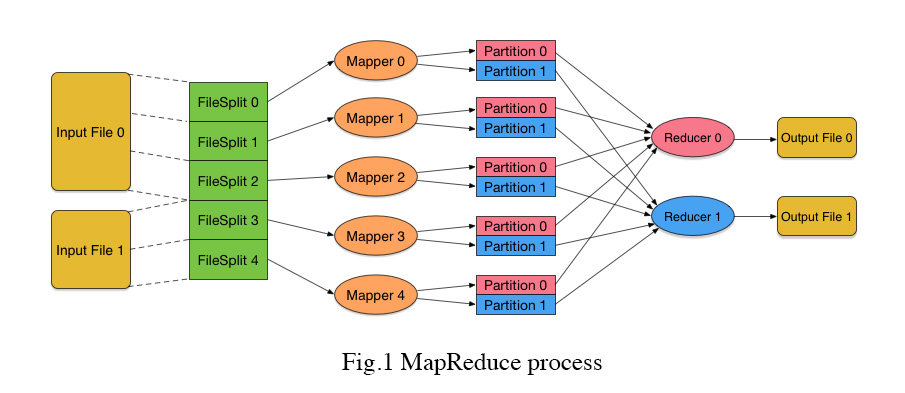
- 资瓷输入多个文件;
- 把每个文件进行逻辑分片,分成指定大小的数据块,每个数据块称为InputSplit;
- 由于要处理很大的文件,所以首先必须要进行分片,这样接下来才便于数据块的处理和传输;
- 而且,这里的文件分片是与业务无关的,而非根据hash分片。根据哈希值进行的文件拆分,需要编程人员根据具体统计需求来确定如何进行哈希,比如根据什么字段进行哈希,以及哈希成多少份。而现在的文件分片,只用考虑分片大小就可以了。分片过程与业务无关,意味着这个过程可以写进框架,而无需使用者操心;
- 另外,还需要注意的一点是,这里的分片只是逻辑上的,并没有真正地把文件切成很多个小文件。实际上那样做是成本很高的。所谓逻辑上的分片,就是说每个InputSplit只是指明当前分片是对应哪一个文件、起始字节位置以及分片长度,而非真正的分文件,省去了原本第一步分片的开销;
- 为每一个InputSplit分配一个Mapper任务,它允许调度到不同机器上并行执行。这个Mapper定义了一个高度抽象的map操作,它的输入是一对key-value,而输出则是key-value的列表
- 输入的InputSplit每次传多少数据给Mapper呢?这些数据又是怎么变成key-value的格式的呢?实际上,InputSplit的数据确实要经过一定的变换,一部分一部分地变换成key-value的格式传进Mapper。这个转换过程使用者自己可以指定。而对于一般的文本输入文件来说(比如访问日志),数据是一行一行传给Mapper的,其中value=当前行,key=当前行在输入文件中的位置;
- Mapper里需要对输入的key-value执行什么处理呢?这部分就是需要用户下程序来实现的部分, Hadoop支持多种语言,但大部分还是基于Java的
- Mapper输出的key和value怎么确定呢?这里输出的key很关键。整个系统保证,从Mapper输出的相同的key,不管这些key是从同一个Mapper输出的,还是从不同Mapper输出的,它们后续都会归类到同一个Reducer过程中去处理。比如要统计日活跃,那么这里就希望相同的用户ID最终要送到一个地方去处理(计数),所以输出的key就应该是用户ID;
- Mapper输出的key-value列表,根据key的值哈希到不同的数据分片中,这里的数据块被称为Partition。后面有多少个Reducer,每个Mapper的输出就对应多少个Partition。最终,一个Mapper的输出,会根据(PartitionId, key)来排序。这样,Mapper输出到同一个Partition中的key-value就是有序的了。这里的过程其实有点类似于之前那种方式根据根据哈希值来进行文件拆分的做法,但那里是对全部数据进行拆分,这里只是对当前InputSplit的部分数据进行划分,数据规模已经减小很多了;
- 从各个Mapper收集对应的Partition数据,进行归并排序,然后将每个key和它所对应的所有value传给Reducer处理。Reducer也可以调度到不同机器上并行执行;
由于数据在传给Reducer处理之前进行了排序,所以前面所有Mapper输出的同一个Partition内部相同key的数据都已经挨在了一起,因此可以把这些挨着的数据一次性传给Reducer。如果相同key的数据特别多,那么也没有关系,因为这里传给Reducer的value列表是以Iterator的形式传递的,并不是全部在内存里的列表; - Reducer在处理后再输出自己的key-value,存储到输出文件中。每个Reducer对应一个输出文件;
Hadoop配置
参考官方文档Hadoop: Setting up a Single Node Cluster.
- 在安装的过程中,需要jdk wget不下来,需要加在
--no-cookie --header "Cookie: oraclelicense=accept-securebackup-cookie" - Hadoop跑example.jar的时候出现
ERROR impl.MetricsSystemImpl: Error getting localhost name. Using 'localhost'... java.net.UnknownHostException: xxx: xxx: Temporary failure in name resolution- 在
/etc/hosts中添加ip hostname, like47.75.137.198 gunjianpan具体参见这个Issue
- 在
- bin/hadoop jar 的时候遇到
Exception in thread “main” java.lang.SecurityException: Prohibited package name: java.lang的报错- 实际上是因为class不是在根目录下,导致package包位置与内部写的位置对不上,把class移到根目录就好了, 参考stackoverflow
- 遇到
Class 'KPIPVMapper' must either be declared abstract or implement abstract method 'map(K1, V1, OutputCollector<K2, V2>, Reporter)' in 'Mapper'- 应该是Hadoop版本的问题,修改Map头就好了
public class MyMapper<K extends WritableComparable, V extends Writable> extends MapReduceBase implements Mapper<K, V, K, V>,参考Interface Mapper<K1,V1,K2,V2>
PS: 要注意Maven不是必须的,Maven只是用来引用包的,同样功能也可以通过Gradle实现
- 应该是Hadoop版本的问题,修改Map头就好了
Map, Reduce
PS: Hadoop 1.* 和 2.* 关于Map Reduce的写法不太一样,需针对版本进行学习, 本文资瓷Hadoop 3.1.1
先放code
- prepare class
package com.wyydsb.service.blog.api.controller;
import lombok.AllArgsConstructor;
import lombok.Builder;
import lombok.Data;
import lombok.NoArgsConstructor;
import java.text.ParseException;
import java.text.SimpleDateFormat;
import java.util.ArrayList;
import java.util.Calendar;
import java.util.Date;
import java.util.List;
import java.util.Locale;
import java.util.stream.Collectors;
@Builder
@Data
@NoArgsConstructor
@AllArgsConstructor
public class KPI {
private String remote_addr;
private String time_local;
private String request;
private String status;
private String body_bytes_sent;
private String http_referer;
private String http_user_agent;
private Integer valid;
@Override
public String toString() {
StringBuilder sb = new StringBuilder();
sb.append("valid:" + this.valid);
sb.append("\nremote_addr:" + this.remote_addr);
sb.append("\ntime_local:" + this.time_local);
sb.append("\nrequest:" + this.request);
sb.append("\nstatus:" + this.status);
sb.append("\nbody_bytes_sent:" + this.body_bytes_sent);
sb.append("\nhttp_referer:" + this.http_referer);
sb.append("\nhttp_user_agent:" + this.http_user_agent);
return sb.toString();
}
/**
* line split
*/
private static KPI parser(String line) {
KPI kpi = new KPI();
String[] arr = line.split(" ", 12);
if (arr.length > 11) {
kpi.setRemote_addr(arr[0]);
kpi.setTime_local(arr[3].substring(1));
kpi.setRequest(arr[5].substring(1));
kpi.setBody_bytes_sent(arr[9]);
kpi.setStatus(arr[8]);
kpi.setHttp_referer(arr[10]);
kpi.setHttp_user_agent(arr[11]);
if (kpi.getStatus().matches("^\\d{3}")) {
if (Integer.parseInt(kpi.getStatus()) == 301) {
kpi.setValid(2);
} else if (Integer.parseInt(kpi.getStatus()) != 200) {
kpi.setValid(0);
} else {
kpi.setValid(1);
}
} else {
kpi.setValid(0);
}
} else {
kpi.setValid(0);
}
return kpi;
}
private Date yesterday() {
final Calendar cal = Calendar.getInstance();
cal.add(Calendar.DATE, -1);
return cal.getTime();
}
/**
* filter spider
*/
public static KPI filterPVs(String line) {
KPI kpi = parser(line);
List<String> keywordList = new ArrayList<>();
keywordList.add("spider");
keywordList.add("taishan");
if (kpi.getHttp_user_agent() != null && keywordList.stream().filter(key -> !kpi.getHttp_user_agent().contains(key)).collect(Collectors.toList()).size() != keywordList.size()){
kpi.setValid(0);
}
return kpi;
}
public static Boolean isYesterday(KPI kpi) {
try {
SimpleDateFormat dfAgo = new SimpleDateFormat("dd/MMM/yyyy:HH:mm:ss", Locale.US);
SimpleDateFormat dfAfter = new SimpleDateFormat("yyyyMMdd");
Date textTime = dfAgo.parse(kpi.getTime_local());
return dfAfter.format(textTime).equals(dfAfter.format(kpi.yesterday()));
} catch (ParseException e) {
e.printStackTrace();
return false;
}
}
public static void main(String args[]) {
String line = "103.192.224.177 - - [4/Oct/2018:17:54:00 +0800] \"GET / HTTP/1.1\" 301 612 \"-\" \"Mozilla/5.0 (Macintosh; Intel Mac OS X 10_13_6) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/70.0.3526.0 Safari/537.36\"";
System.out.println(filterPVs(line).toString());
}
}
- Map Reduce class
package com.wyydsb.service.blog.api.controller;
import java.io.IOException;
import java.util.Iterator;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapred.FileInputFormat;
import org.apache.hadoop.mapred.FileOutputFormat;
import org.apache.hadoop.mapred.JobClient;
import org.apache.hadoop.mapred.JobConf;
import org.apache.hadoop.mapred.MapReduceBase;
import org.apache.hadoop.mapred.Mapper;
import org.apache.hadoop.mapred.OutputCollector;
import org.apache.hadoop.mapred.Reducer;
import org.apache.hadoop.mapred.Reporter;
import org.apache.hadoop.mapred.TextInputFormat;
import org.apache.hadoop.mapred.TextOutputFormat;
public class PersonVersion {
public static class MapPre extends MapReduceBase implements
Mapper<LongWritable, Text, Text, IntWritable> {
private IntWritable one = new IntWritable(1);
private Text word = new Text();
@Override
public void map(LongWritable key, Text value, OutputCollector<Text, IntWritable> output, Reporter reporter)
throws IOException {
KPI kpi = KPI.filterPVs(value.toString());
if (kpi.getValid() == 1 && kpi.getRemote_addr() != null) {
word.set(kpi.getRemote_addr());
output.collect(word, one);
}
}
}
public static class MapSpider extends MapReduceBase implements
Mapper<LongWritable, Text, Text, IntWritable> {
private IntWritable one = new IntWritable(1);
private Text word = new Text();
@Override
public void map(LongWritable key, Text value, OutputCollector<Text, IntWritable> output, Reporter reporter)
throws IOException {
KPI kpi = KPI.filterPVs(value.toString());
if (kpi.getValid() == 0 && kpi.getRemote_addr() != null) {
word.set(kpi.getRemote_addr());
output.collect(word, one);
}
}
}
public static class MapPreSection extends MapReduceBase implements
Mapper<LongWritable, Text, Text, IntWritable> {
private IntWritable one = new IntWritable(1);
private Text word = new Text();
@Override
public void map(LongWritable key, Text value, OutputCollector<Text, IntWritable> output, Reporter reporter)
throws IOException {
KPI kpi = KPI.filterPVs(value.toString());
if (kpi.getValid() == 1 && kpi.getRemote_addr() != null && KPI.isYesterday(kpi)) {
word.set(kpi.getRemote_addr());
output.collect(word, one);
}
}
}
public static class MapSpiderSection extends MapReduceBase implements
Mapper<LongWritable, Text, Text, IntWritable> {
private IntWritable one = new IntWritable(1);
private Text word = new Text();
@Override
public void map(LongWritable key, Text value, OutputCollector<Text, IntWritable> output, Reporter reporter)
throws IOException {
KPI kpi = KPI.filterPVs(value.toString());
if (kpi.getValid() == 0 && kpi.getRemote_addr() != null && KPI.isYesterday(kpi)) {
word.set(kpi.getRemote_addr());
output.collect(word, one);
}
}
}
public static class MapIn extends MapReduceBase implements
Mapper<LongWritable, Text, Text, IntWritable> {
private IntWritable one = new IntWritable(1);
private Text word = new Text(" ");
@Override
public void map(LongWritable key, Text value, OutputCollector<Text, IntWritable> output, Reporter reporter)
throws IOException {
if(value.toString() != null) {
output.collect(word, one);
}
}
}
public static class Reduce extends MapReduceBase implements
Reducer<Text, IntWritable, Text, IntWritable> {
private IntWritable result = new IntWritable();
@Override
public void reduce(Text key, Iterator<IntWritable> values,
OutputCollector<Text, IntWritable> output, Reporter reporter)
throws IOException {
Integer sum = 0;
while (values.hasNext()) {
sum += values.next().get();
}
result.set(sum);
output.collect(key, result);
}
}
private static void runJobPv(String inputDir, String outputDir, String jobName, Class<? extends Mapper> mapClass,
Class<? extends Reducer> reduceClass) throws Exception {
JobConf conf = new JobConf(PersonVersion.class);
conf.setJobName(jobName);
conf.setMapOutputKeyClass(Text.class);
conf.setMapOutputValueClass(IntWritable.class);
conf.setOutputKeyClass(Text.class);
conf.setOutputValueClass(IntWritable.class);
conf.setMapperClass(mapClass);
conf.setCombinerClass(reduceClass);
conf.setReducerClass(reduceClass);
conf.setInputFormat(TextInputFormat.class);
conf.setOutputFormat(TextOutputFormat.class);
FileInputFormat.setInputPaths(conf, inputDir);
FileOutputFormat.setOutputPath(conf, new Path(outputDir));
JobClient.runJob(conf);
}
public static void main(String[] args) throws Exception {
Long start = System.currentTimeMillis();
String inputDir = args[0];
String outputDir = args[1];
// Total
runJobPv(inputDir, outputDir, "KPIPv", MapPre.class, Reduce.class);
runJobPv(outputDir, outputDir + "-1", "KPIUv", MapIn.class, Reduce.class);
// Total spider
runJobPv(inputDir, outputDir + "-2", "KPIPVSpider", MapSpider.class, Reduce.class);
runJobPv(outputDir + "-2", outputDir + "-3", "KPIUVSpider", MapIn.class, Reduce.class);
// Section
runJobPv(inputDir, outputDir + "-4", "KPIPvSection", MapPreSection.class, Reduce.class);
runJobPv(outputDir + "-4", outputDir + "-5", "KPIUv", MapIn.class, Reduce.class);
// Section spider
runJobPv(inputDir, outputDir + "-6", "KPIPVSpiderSection", MapSpiderSection.class, Reduce.class);
runJobPv(outputDir + "-6", outputDir + "-7", "KPIUVSpider", MapIn.class, Reduce.class);
Long end = System.currentTimeMillis();
System.out.println("spend:"+(end-start)+"ms");
System.exit(0);
}
}
嗯 很久没写JAVA了 很是恐惧
第一个类实现的是数据预处理,对log行数据进行split,并根据status、agent信息进行是否是爬虫的判断
然后我们的class引用了lombok.jar对set,get进行简化
所以在用javac编译成class之前,需要设置下classpath-中文就是依赖包(不用写一大堆-cp了)
加上hadoop所需的一些jar包, 总共需要设置环境变量如下
export HADOOP_CLASSPATH=${JAVA_HOME}/lib/tools.jar
export HADOOP_HOME=/usr/src/hadoop-3.1.1
export CLASSPATH=$($HADOOP_HOME/bin/hadoop classpath):$CLASSPATH # hadoop jar
export CLASSPATH=$HADOOP_HOME/lombok.jar:$CLASSPATH # lombok.jar
export HADOOP_INSTALL=$HADOOP_HOME
export HADOOP_MAPRED_HOME=$HADOOP_HOME
export HADOOP_COMMON_HOME=$HADOOP_HOME
export HADOOP_HDFS_HOME=$HADOOP_HOME
export YARN_HOME=$HADOOP_HOME
export HADOOP_COMMON_LIB_NATIVE_DIR=$HADOOP_HOME/lib/native
export PATH=$PATH:$HADOOP_HOME/sbin:$HADOOP_HOME/bin
java程序应该比较简单,大家看一下应该就懂了 主要是配置
## 编译
javac KPI.java PersonVersion.java
## 打jar
jar cf PersonVersion.jar KPI*.class PersonVersion*.class
## 解jar 运行
bin/hadoop jar PersonVersion.jar PersonVersion log logresult 'dfs[a-z.]+'
后续
- 实际生产过程中日志数据有很多来源,格式也会比较复杂。在数据统计之前会有一个很重要的ETL过程(Extract-Transform-Load)。
- 以上在介绍MapReduce的时候,是仿照Hadoop里的相关实现来进行的,而Hadoop是受谷歌的Jeffrey Dean在2004年发表的一篇论文所启发的。那篇论文叫做《MapReduce: Simplified Data Processing on Large Clusters》
- Hadoop全家桶还没开始讲
- 其中YARN是Hadoop集群的资源管理和任务调度监控系统
- HDFS是为了让Mapper和Reducer在不同的机器上都能对文件进行读写,而实现的一个分布式文件系统
- Hadoop和HDFS的一个重要设计思想是,移动计算本身比移动数据成本更低。因此,Mapper的执行会尽量就近执行。这部分本文没有涉及。
- 关于输入的InputSplit的边界问题。原始输入文件进行逻辑分块的时候,边界可能在任意的字节位置。但对于文本输入文件来说,Mapper接收到的数据都是整行的数据,这是为什么呢?这是因为对一个InputSplit进行输入处理的时候,在边界附近也经过了特殊处理。具体做法是:在InputSplit结尾的地方越过边界多读一行,而在InputSplit开始的时候跳过第一行数据。
- 在每个Mapper结束的时候,还可以执行一个Combiner,对数据进行局部的合并,以减小从Mapper到Reducer的数据传输。但是要知道,从Mapper执行,到排序(Sort and Spill),再到Combiner执行,再到Partition的生成,这一部分相当复杂,在实际应用的时候还需深入理解、多加小心。